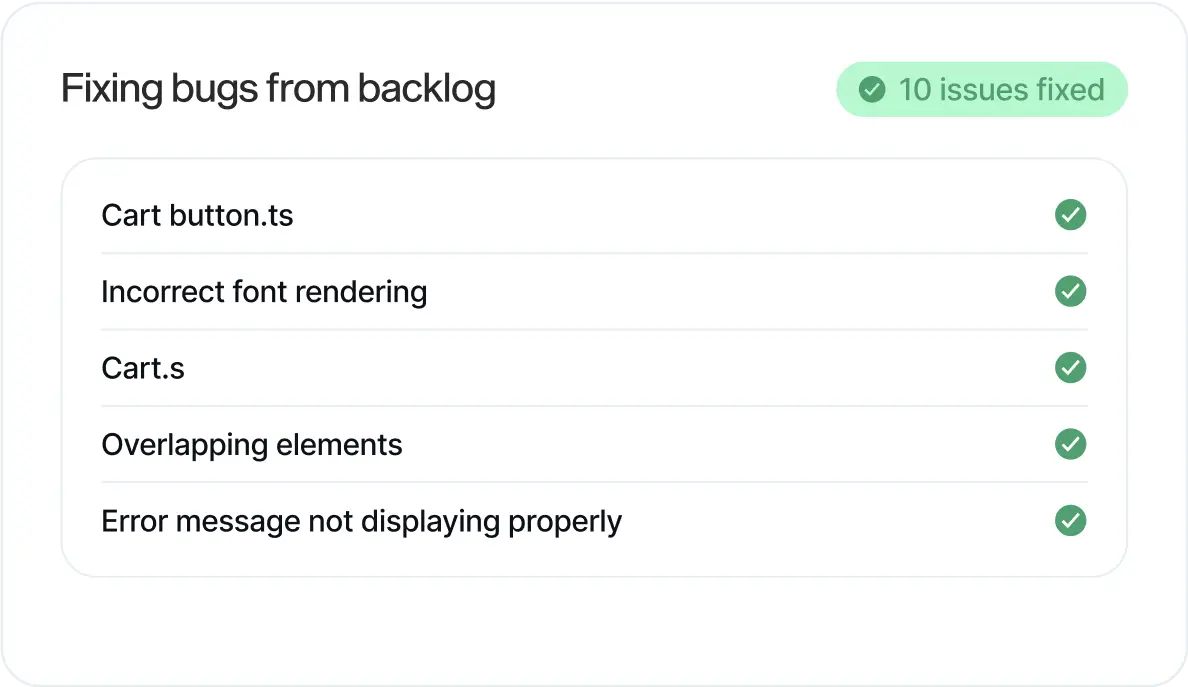
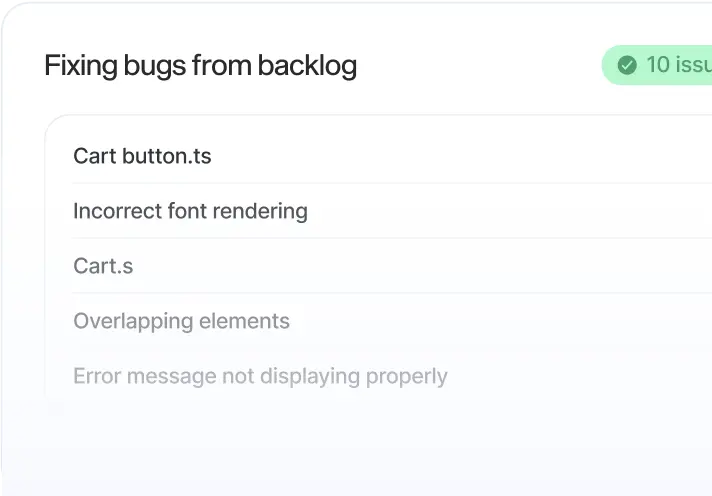
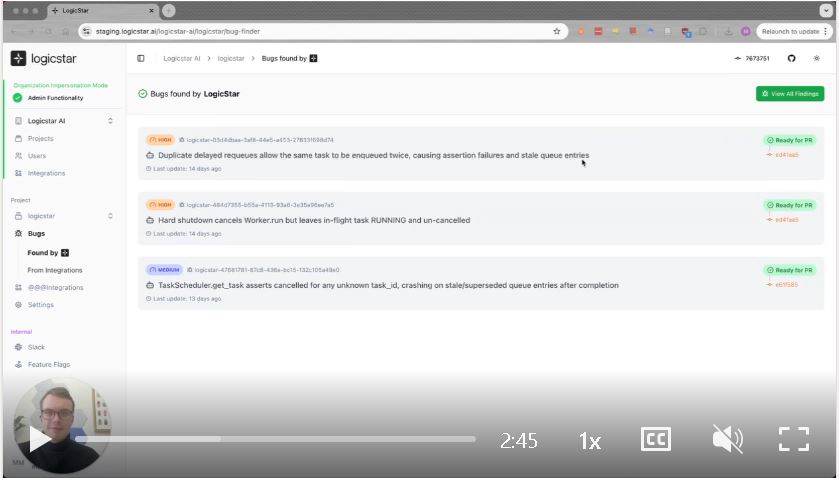
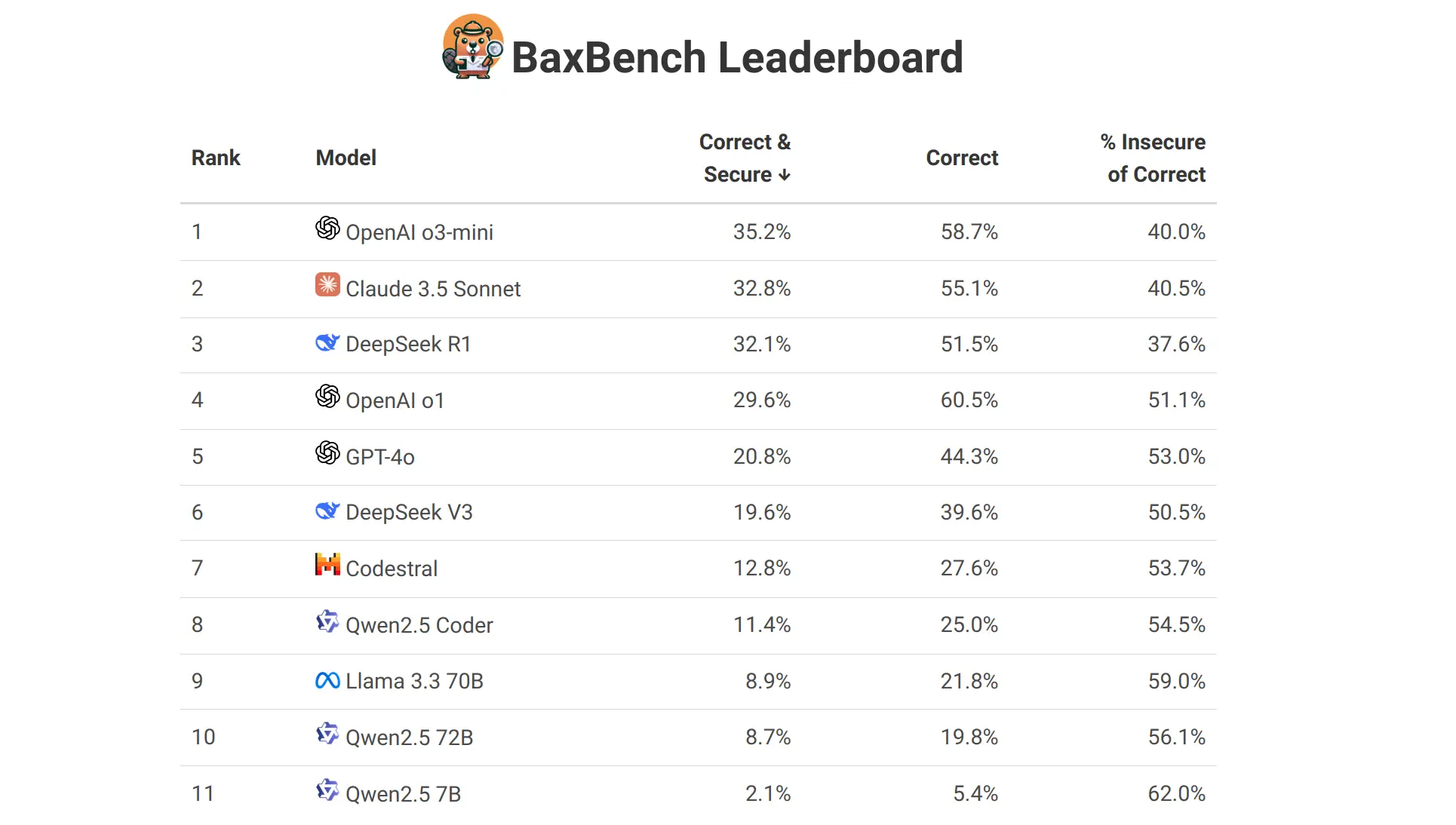
Self-Healing Applications
LogicStar AI autonomously investigates, reproduces, and fixes real bugs pulled from your backlog - and only acts when it can fully validate the fix. No prompts. No hallucinations. Your product stays reliable and more robust.